
Spying on James Bond with Node.js

Sure, Node.js has gotten a ton of attention lately. It is fast and powerful, especially when combined with the over 200,000 packages in npm. But, I'm sure you've asked yourself, is it powerful enough to help take down the world's greatest super spy?
I was reading about a library named Knwl.js when the idea came to me - as depicted in the image below.

So I built a program that uses data about all of Bond's prior activities and parse this for all of his prior known locations. Narrowing down his prior destinations should help us track him down and, obviously, destroy him...albeit in a slow and complicated fashion.

Of course, Knwl.js can do more than simply help track down and destroy James Bond. It can help you identify dates, times, emails, places, links, phone numbers and more in any block of content. This opens up a ton of possibilties for analyzing and responding to content, specifically user generated content. But enough of that fluff, let's focus on our mission: James Bond!
Developing the Plan
The first thing I needed to do was find a way to gather all of James Bond's prior locations. Thankfully, for a supposedly "secret" agent, all of his missions are well chronicled on the James Bond wiki. But, how do I get the text?
Wikia API
Well, the good news is that Wikia, the host of the James Bond wiki, offers an API. This should be easy then, you may be thinking - ah, if an evil plan ever were!
The first set of bad news is that the API is not enabled for cross-domain requests (via CORS). Knwl.js actually works in the browser, but there goes my in-browser solution. Instead, I'll use Node.js.
The next set of bad news is that the API only gives article summaries and not the full text. So, I'll have to devise a solution for getting the full contents of the page.
After a bit of research, I was able to find a way to get all the articles in the "James Bond Films" category, which contained the URLs for the wiki pages for each movie (and a few extra pages, but good enough). The URL for the API is http://jamesbond.wikia.com/api/v1/Articles/List?category=James_Bond_films&limit=50 - click it if you'd like to see a sample of the output.
To get this information within my Node application, I'll use request (where apiURL below is the above URL).
request(apiURL, function (error, response, body) {
...
}Scraping the Contents
At this point, all I have is a JSON response containing the URLs for all the movie wiki pages. Next, I need to somehow scrape the contents of these pages to get the full description. Fortunately for my devious scheming, Smashing Magazine had a recent article on how to scrape the web with Node.js which discusses cheerio.
While request will do the actual get request to the wiki, cheerio will allow me to parse it so that I only pass the main content to Knwl.js.
First, I need to parse the JSON result from earlier and loop through all the movies.
var baseURL = "http://jamesbond.wikia.com",
allMovies = JSON.parse(body);
allMovies.items.forEach(function (movie) {
movieURL = baseURL + movie.url;
...
}For each movie, I am going to use the URL and perform another request on each. Lucky for us there are only about 30 results - too many results and this method would be impractical, both for me and for Wikia.
request(movieURL, function (error, response, body) {
...
}Next, I'll use cheerio to parse the body of the page and get me only the main content. Unfortunately, there was no guaranteed consistency for the wiki pages or I'd love to simply get the detailed summary portion. Instead, I get the entire contents of the main body text div (obviously, this is very fragile since I am relying on a specific ID existing, but it wouldn't be a good evil plan if it wasn't open to being easily thwarted).
$ = cheerio.load(body);
movieDescription = $("#mw-content-text").text();Ok. I've got all the details about Bond's prior missions. It's time to get the list of places James Bond has been.
Using Knwl.js in Node
Now that I have the text I need, I'm ready to parse it with Knwl.js. First, I need to instantiate an instance of Knwl.js.
knwlInstance = new Knwl('english');Knwl.js is built in such a way that all of the functionality and logic to find what you are looking for (places, emails, times, etc.) is built into plugins. There are a number of default plugins that come with the install as well as some experimental ones already available. This also means that you could write your own plugin, if you chose to, to parse the text for some other kind of item.
What I want is the places plugin, so I need to import it (note that the location of the plugin depends on where npm install puts your plugins).
knwlInstance.register('places', require('knwl.js/default_plugins/places'));At this point, I can use Knwl.js to search the movieDescription I got from cheerio and get me an array of places within it.
knwlInstance.init(movieDescription);
places = knwlInstance.get('places');Now it's time to put all the pieces together!

The Program
I decided to implement this as a command line tool along the lines of one of my mentors, Max Zorin.

Did you know that you can use npm modules in NativeScript? In theory, this could be built as a native mobile app using JavaScript...and I could track Bond while on the go!
Taking all the pieces above, I get the list of movie URLs, loop through all the movies, scrape the page using request, pull the text from the body using cheerio, extract a list of places using Knwl.js and then, finally, assemble the data and output it to the console. Since this process can be a bit slow, I've also added in a console progress bar to indicate the status of the parsing.
First, let's look at the full code.
Some additional things to point out are that I've created the variable knownLocations so that I can indicate when a location comes up more than once across the various films. I even create a tally of how many times Mr. Bond shows up at a particular location within the given film description.
Additionally, completedRequests simply tracks when all of the URLs have been loaded and parsed. The request module isn't promise based, which made this less straightforward than it probably could have been. A future version might have used node-promise to overcome this problem...if I needed a future version! What's the point? Bond will be dead by then.
Let's see this in action.
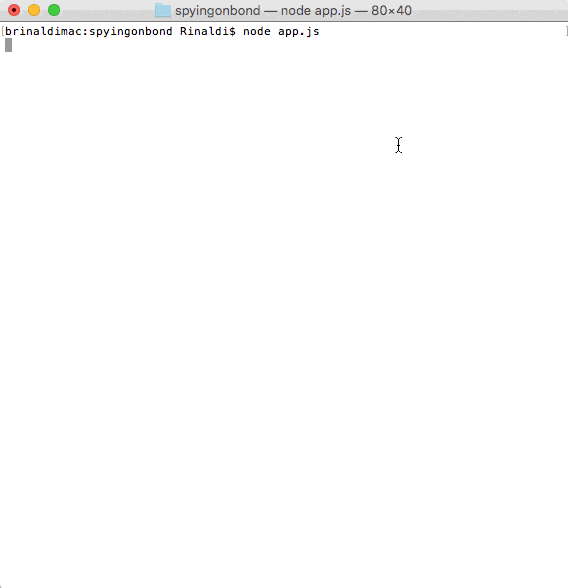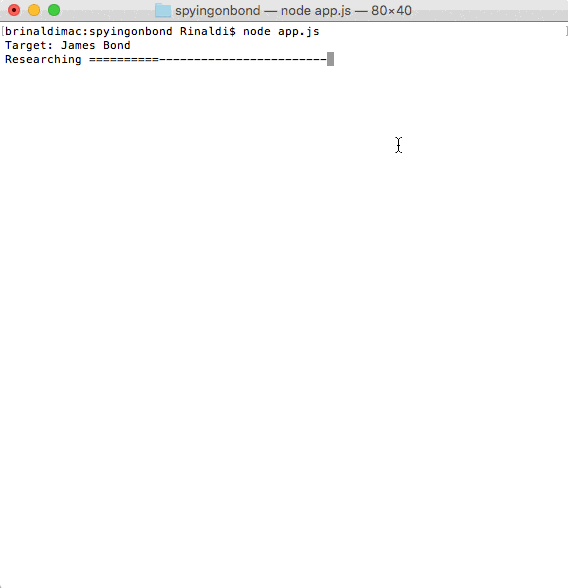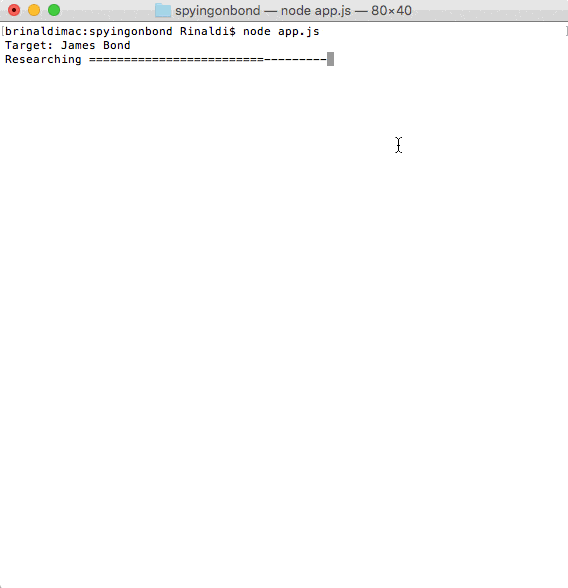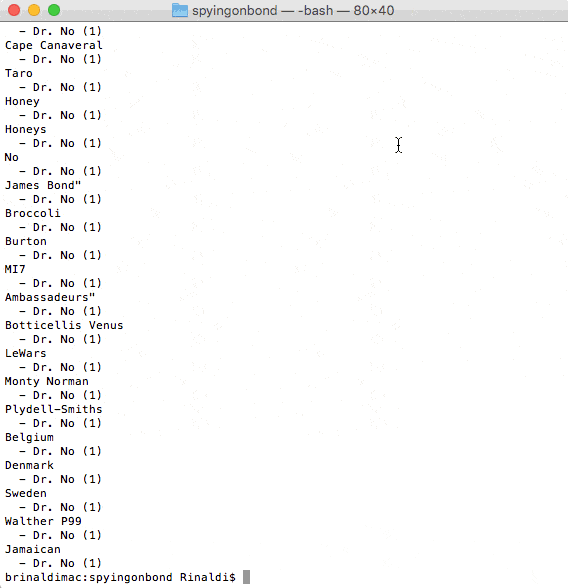
The actual results are quite long and appear on the screen so quickly that it can be hard to see in the animated gif above. Here's a snippet of some of the results.
Perdition
- Skyfall (1)
- Quantum of Solace (1)
Vauxhall Cross
- Skyfall (1)
Duntrune Castle
- Skyfall (1)
IMDb
- Skyfall (1)
Auric Goldfinger:
- Goldfinger (1)
Goldfinger
- Goldfinger (5)
- On Her Majesty's Secret Service (1)
- Thunderball (1)
Kentucky
- Goldfinger (1)
Goldfingers
- Goldfinger (1)
Pussy Galore
- Goldfinger (1)
Oddjob
- Goldfinger (1)
President
- Goldfinger (1)
Guy Hamilton
- Goldfinger (1)
- Thunderball (1)
Fontainebleau Hotel;
- Goldfinger (1)
Florida
- Goldfinger (1)
Pinewood
- Goldfinger (1)
- Quantum of Solace (1)Perdition...ok. Vauxhall Cross...ok. Duntrune Castle...ok. IMDb...huh? Auric Goldfinger...that's a person, not a place! These results are a mess! Sure, there are tons of places here, but lots of false positives too! This plan is turning out to be less Ernst Stavro Blofeld and more Dr. Evil.

What Gives?
So, understanding what went wrong with my plan involves digging into the code for Knwl.js and the places plugin a bit.
Knwl.js' places plugin relies on two different methods of determining a place. The first is a simple list of country names that it searches for matches. However, the second is a list of trigger words that would indicate that the text following is referring to a place.
this.triggers = [['at'], ['near'], ['close', 'to'], ['above'], ['below'], ['to'], ['leaving'], ['arriving', 'at']];As you can see, the triggers can be very generic, which would lead to a ridiculous number of false positives. To mitigate this issue, Knwl.js also includes a list of false positives, or common words that might come after the triggers but not actually be a place.
this.falsePlaces = ['January', 'February', 'March', 'April', 'May', 'June', 'July', 'August', 'September', 'October', 'November', 'December', 'His', 'He', 'Her', 'Hers', 'Who', 'Whom', 'Whose', 'PM', 'AM', 'The'];Unfortunately, the list of false positives is relatively short.
So, taking one of the false positives in the results posted earlier ("IMDb") and checking the wiki page for Skyfall, which it appears in, I see the following:

So the word "to" was a trigger but "IMDb" was not a false positive. To get this to work better, I'd need a way to remove some triggers or pass in a longer list of false positives. Unfortunately, for now, there doesn't appear to be a built-in way to do this. I could copy the places plugin code and tweak it to make my own modified plugin for Knwl.js, but, it turns out that I am not a persistent enough bad guy to take my mission that far.
Doing Useful Things with Knwl.js
Despite failing in my mission, I had fun...and really, that's all we Bond villains want, is to have fun, after all.

That being said, there are a ton of productive things you could do with Knwl.js. I think it could be especially useful for searching user generated content (whether from internal users in a CMS or external users in a community site) and offering context-related links or information. The project has a nice demo showing how this could work with an email or message board post, for instance.
Now, if you don't mind, I must return to my lair.


Brian Rinaldi
Brian Rinaldi is a Developer Advocate at Progress focused on the Kinvey mobile backend as a service. You can follow Brian via @remotesynth on Twitter.
Comments
All articles
Topics
Latest Stories
in Your Inbox
Subscribe to be the first to get our expert-written articles and tutorials for developers!
All fields are required